Was ist ein Convolutional Neural Network?
Wenn ihr die Grundlagen der neuronalen Netze kennt und euch das erste Mal mit Bilderkennung beschäftigt, dann werdet ihr wahrscheinlich schon von einem Convolutional Neural Network oder CNN gehört haben. Verwendet werden sie meist bei allen Themen rund um Bildverarbeitung und -erkennung, allerdings gibt es auch andere Bereiche, in denen CNNs beachtliche Resultate erzielen. Es gibt eine Reihe bekannter CNN-Architekturen, die bereits erprobt sind und sich für verschiedene Anwendungsbereiche anbieten. Es gibt zum Beispiel AlexNet, ResNet und Yolo. In den meisten Fällen ist es einfacher, eine bekannte Architektur zu verwenden, anstatt neu aufzubauen.
Aufbau eines Convolutional Neural Network
Zu aller erst müssen wir festhalten, dass Convolutional Neural Networks in dieser Form nicht existieren. Es geht eher um das Auftreten eines Convolutional Layer. Ein CNN ist also ein neuronales Netz, welches mindestens ein Convolutional Layer enthält.
Aufbau eines Bildes
Jedes Bild wird aus den Farben der einzelnen Pixel definiert. Ein Bild hat also eine bestimmte Anzahl von Pixeln und zu jedem Pixel wird eine Farbe abgespeichert. Die Farben entstehen normalerweise aus drei verschiedenen RGB-Kanälen. RGB steht für die drei Farben Rot, Grün und Blau. Kombiniert man diese drei Farben in unterschiedlicher Stärke, so entstehen daraus eindeutige Farben.

Wir sehen hier die Repräsentation eines Bildes mit vier Pixeln in Höhe und Breite und den RGB-Werten, welches wir im Folgenden für Beispiel-Rechnungen verwenden werden. Ein Bild mit definierter Höhe, Breite und den drei RGB-Werten ist der Eingang eines Convolutional Neural Network.
Was passiert in einem Convolutional Neural Network?
Erhält das erste Layer nun als Eingang unser Bild, so nutzt es Kernel um neue Werte zu errechnen. Ein Kernel, oder auch Filter genannt, ist eine kleine Matrix aus Gewichten die mit den Werten multipliziert werden und neue Werte ergeben. Dabei gibt es für jeden Kanal ein Kernel.
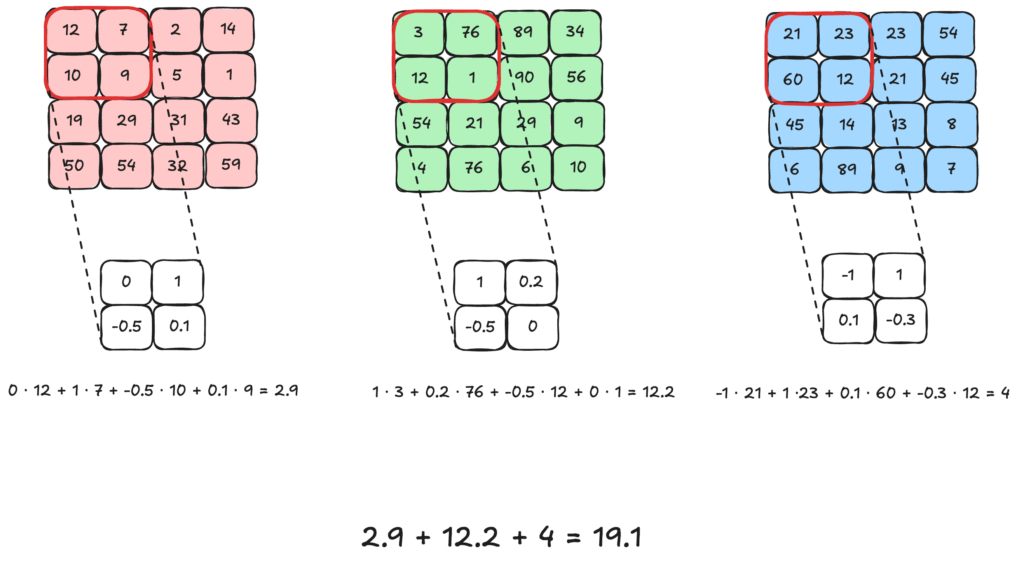
Die Multiplikation mit dem Kernel werden hier beispielhaft in der oberen linken Ecke berechnet. Danach wandern die Kernel über das Bild und führen die Multiplikation immer wieder durch. Daraus ergibt sich ein neues Bild, welches aber nur einen Kanal hat.
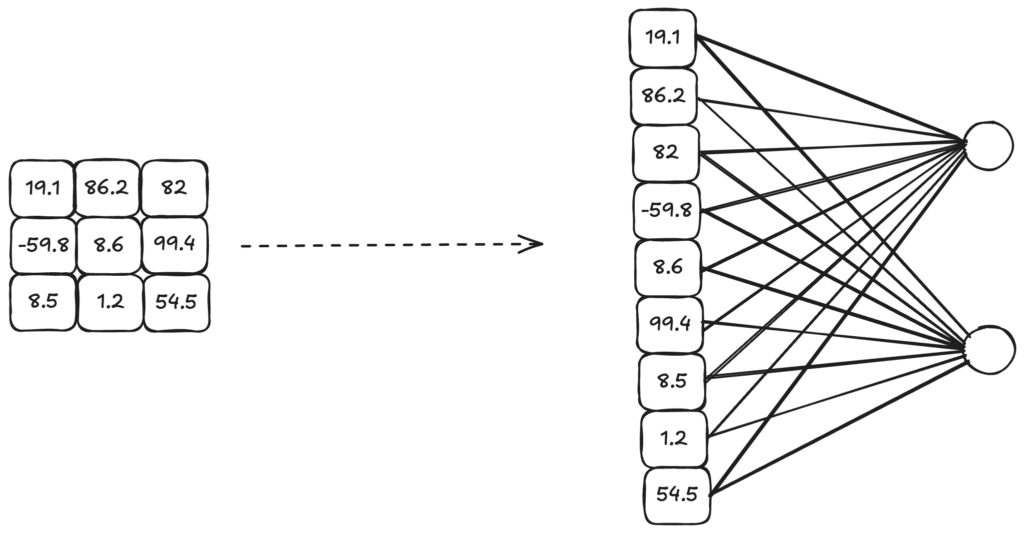
Das entstandene Bild kann wiederum als Eingang für ein weiteres CNN-Layer verwendet werden oder es kann optional noch ein Bias addiert werden. Möchte man eine Klassifikation oder ähnliches haben, so muss das entstandene Bild in einen Vektor transformiert werden. Dies geschieht indem die Werte des Bildes nacheinander aufgereiht werden.
Einfluss der Kernelgröße
Die Kernelgröße kann variabel eingestellt werden und sollte nicht unbedacht gelegt werden. Ein größeres Kernel kann sehr große, globale Objekte erfassen. Daher bietet sich in den vorderen Schichten meist eine höhere Kernelgröße an. Zum Beispiel verwendet ein AlexNet ein 7×7-Kernel. Kleinere Kernel erkennen wiederum feinkörnige Details in den Bildern und sind daher bei kleinen Zielen oder in hinteren Schichten geeignet. Große Kernel erhöhen aber wiederum den Rechenaufwand und neigen auch immer zu zu starkem Overfitting. Daher sollten gerade große Kernel mit Bedacht gewählt werden und nur in den vorderen Schichten eingesetzt werden.
Wie kann ein CNN mehrere Output-Channel haben?
In unserem ersten Beispiel hatten wir drei Input-Channel und haben daraus einen einzelnen Output-Channel erhalten. Dies muss nicht der Normalfall sein, es ist auch möglich, die Anzahl der Channel zu behalten oder sogar zu erweitern. Dies funktioniert, indem es für jeden Input-Channel mehr als ein Kernel gibt. Im Beispiel hatten wir pro Channel nur ein Kernel und haben diese dann addiert. Für n-viele Output-Channel benötigen wir also für jeden Channel auch n Kernel. Diese Kernel werden auch multipliziert und dann mit den anderen Ergebnissen für denselben Output-Channel addiert, z. B. wird für den dritten Output-Channel das Ergebnis der Multiplikation des dritten Kernel von jedem Input-Channel addiert. In Summe wären dies Input-Channel · Output-Channel viele Kernel.
Was ist Padding?
Da das Kernel nur mit anderen 2×2 Bereichen multipliziert werden kann, werden äußere Pixel weniger beachtet als innere. Das kann man sehen, indem man sich in dem Output-Bild anschaut an wie vielen Ergebnissen äußere und ein innere Werte beteiligt waren. Die kann zu Problemen führen, wenn wir z.B. Objekte erkennen wollen und diese am Rand platziert sind. Um dieses Problem zu verhindern, gibt es das Padding. Dabei wird eine künstliche Reihe mit einem bestimmten Wert (hier die 1) außen um das Bild platziert. Die Multiplikation wird auch mit den künstlichen Werten wie bekannt durchgeführt. Auch hier ergibt sich wieder ein Output-Bild. Dabei muss beachtet werden, dass das Output-Bild andere Maße haben wird, als ohne Padding.
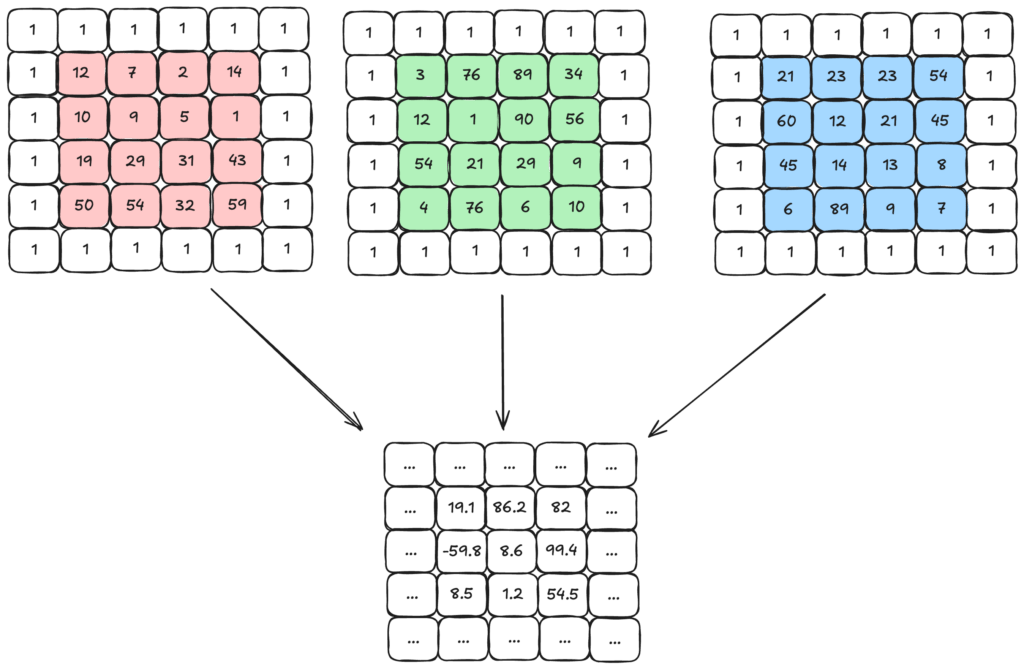
Was sind Probleme des Padding?
Die Vorteile von Padding haben wir bereits erläutert, allerdings kann es auch Probleme mit sich bringen. Daher sollte die Anwendung immer genau abgewogen und getestet werden. Das größte Problem ist die Wahl der Werte der künstlichen Reihe. Hier gibt es zwei gängige Möglichkeiten: ein fester Wert oder der Wert des anliegenden Pixels. Verwendet man den gleichen Wert der umliegenden Pixel, so kann es dazu führen, dass Ränder überrepräsentiert werden. Verwendet man einen bestimmten Wert, so können aber für das Modell auch Muster entstehen, die aber eigentlich gar nicht existieren. Zudem vergrößert Padding auch die Maße des Outputs.
Was ist Stride in einem Convolutional Neural Network?
Bisher haben wir das Kernel immer ein Feld weiter nach rechts verschoben und am Ende der Zeile in die nächste Zeile. Dabei spricht man von einem Stride von 1. Der Stride gibt die Anzahl an Feldern, die das Kernel weit wandert. Dabei kann es für Höhe und Breite unterschiedliche Werte geben, das Kernel kann z.B. immer um zwei Felder und der Breite wandern und um drei in der Höhe. Auch hierbei verändert ein anderer Wert natürlich die Größe und Werte des Output-Bildes.
Warum wird Stride verwendet?
Die Verwendung eines Strides dient vor allem der Verkleinerung von sehr großen Bildern. Man stelle sich vor, dass ein Bild extrem hochauflösend ist und wir z.B. Tiere erkennen wollen, dann ist es nicht nötig, dass ein Filter über jeden Pixel wandert, sondern reicht aus wenn er immer mehrere Pixel überspringt. Dies verringert die Anzahl an Rechenoperationen und sorgt auch für einen kleineren Output, was wichtig ist, um Informationen zu aggregieren.
Was ist Dilation?
Bei der Implementierung eines Convolutional Layer wird euch der Parameter Dilation auffallen. Der Standardwert liegt bei 1, er kann aber auch beliebig angepasst werden. Doch was verändert Dilation und wann und warum sollte man es verwenden?
Was macht Dilation in einem Convolutional Neural Network?
Dilation bedeutet zu deutsch “Ausdehnung”, es gibt also die Breite der Ausdehnung einer Berechnung an. Das klingt kompliziert, wird aber ganz einfach umgesetzt.
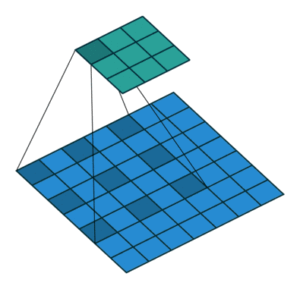
Anstatt, dass ein Kernel mit nebeneinander liegenden Werten kalkuliert wird, wird zwischen den Werten ein Abstand gelassen. Im dem Bild sieht man zum Beispiel ein 3×3-Kernel, welches über das Bild wandert und immer die Werte mit einem Abstand von 2 beachtet, der Wert für den Parameter Dilation wäre also 2. Der Output ergibt sich dann in dem oberen grünen Feld.
Wozu wird Dilation verwendet?
Dilation in Convolutional Layers wird verwendet, um das beachtete Feld zu vergrößern, ohne die Anzahl der Parameter zu erhöhen oder die Auflösung der Ausgabe zu verringern. Dies geschieht durch das Einfügen von Lücken in den Kernel, wodurch das Netzwerk Informationen aus einem größeren Bereich erfassen kann. Es ist besonders nützlich in Aufgaben wie Segmentierung, Zeitreihenanalyse und Objekterkennung, da es weiträumigen Kontext effizient modelliert und dabei die räumliche Auflösung beibehält.
Entstehung der Output-Größen in einem Convolutional-Layer
Wie zuvor erklärt hat jeder Parameter einen Einfluss auf die Größe des Outputs und die Anzahl der Channel. Zum Beispiel bei einer Klassifikation muss der Output ganz bestimmte Dimensionen haben und um die Dimensionen eines Outputs schon vorher zu wissen bietet sich die folgende Formel an:
$$H_{out}=\frac{H_{in}+2·\text{padding}-\text{dilation}·(\text{kernel size-1)-1}}{\text{stride}}+1$$
Für die Breite ist die Formel logischerweise gleich, nur mit den Breiten-Werten als Eingang.
Fazit – Convolutional Neural Network
Convolutional Neural Networks sind ein mächtiges Werkzeug in der Bildverarbeitung und haben die Art und Weise, wie wir Bilder automatisiert analysieren können, revolutioniert. Die verschiedenen Parameter wie Kernel-Größe, Padding, Stride und Dilation ermöglichen es uns, die Netzwerke flexibel an unterschiedliche Aufgabenstellungen anzupassen.
Dabei ist es wichtig zu verstehen, dass jeder dieser Parameter Vor- und Nachteile mit sich bringt und sorgfältig gewählt werden muss. Die Wahl der richtigen Parameter hängt von verschiedenen Faktoren ab, wie der Größe der zu erkennenden Objekte, der verfügbaren Rechenleistung und der gewünschten Ausgabegröße.
Für Einsteiger empfiehlt es sich, mit bewährten CNN-Architekturen wie AlexNet oder ResNet zu beginnen und diese schrittweise an die eigenen Bedürfnisse anzupassen. Mit zunehmendem Verständnis der einzelnen Komponenten können dann auch eigene, spezialisierte Architekturen entwickelt werden.